Пособираем VPLS-сервисы на Huawei. Здесь будет Kompella VPLS, Kompella VPLS + Martini H-VPLS (Mixed). В качестве IGP - ISIS, а в качестве транспорта - RSVP-TE. Стенд соберём в eNSP.
Не по теме
У меня есть старенький сервер с VMware ESXi, 6.0.0, есть виртуальная машина с Windows 10. Развернем на ней eNSP. eNSP использует VirtualBox, поэтому потребуется возможность запускать виртуальные машины внутри вирутальной машины. Это Nested virtualization, и в VMware существует давно. Включается так:
- Стартанем SSH через vSphere Client: Configuration - Security Profile - Properties - SSH - start
- Логинимся на сервер по ssh:
- открываем /etc/vmware/config
- добавляем vhv.enable = “TRUE” Это всё. Здесь побольше информации.
Устанавливаем eNSP, ищем на https://support.huawei.com/ (потребуется учетная запись с правами загрузки продуктов Huawei). Здесь же находим образы для eNSP. Сейчас есть для следующих устройств: NE40E, NE5000E, NE9000, CE, CX, USG6000V.
Теперь, по теме.
Топология, ISIS, RSVP-TE
Соберем топологию на NE40E (здесь подписаны интерфейсы и уже добавлены хосты):
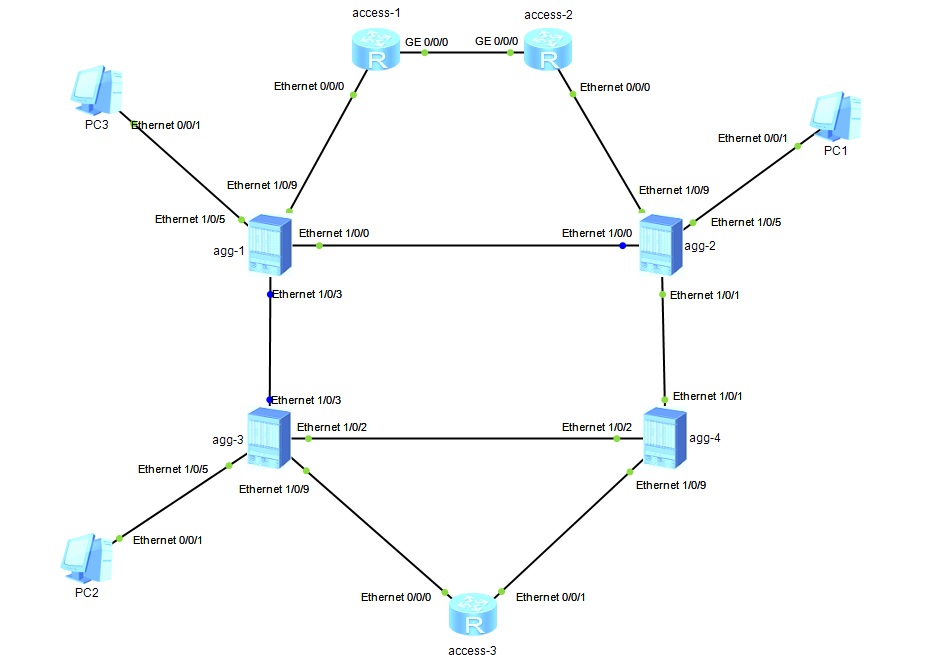
Что имеем:
в качестве IGP - ISIS. Для каждого access-элемента сети существует единственный выход в мир - через agg, поэтому access-маршрутизаторам, находящимся в разных “кольцах доступа”, знать друг о друге совсем не обязательно. Исключить лишние префиксы на access можно разделив ISIS-домен на L1/L2 маршрутизаторы (это будут все agg) и на L1-маршрутизаторы (это будут все access), при этом важно добавить их в разные area. Тогда, мы получим default route на всех L1-access. Это равносильно totally stubby area в OSPF, и это хороший вариант, если ограничиться только маршрутизацией, но нам-то нужно строить LSP, а поверх - VPN. Есть второй вариант - настроить все маршрутизаторы как L2, разделив весь ISIS-домен на инстансы. Каждый инстанс - это отдельный процесс маршрутизации, никак не пересекающийся с остальными. Например, все agg выделим в instance 1, access-1 и 2 добавим в instance 2, а access-3 - в instance 3. Хорошая практика - настроить на всех agg указанные ISIS instance. Зачем? Кратко - затем, чтобы строить LSP между любым access и любым agg, а поверх - “бросать” VPN-сервисы.
agg объединены в RouteReflector (далее RR) cluster’ы (agg-1 + agg-2, agg-3 + agg-4), каждый со своим cluster ID. При выборе одинаковый/разный cluster id нужно помнить, что, если маршрутизатор получил BGP Update, где в поле CLUSTER_LIST указан его собственный cluster id, то такой Update будет отброшен. Это исключает петли. Cluster id нужно выбирать аккуратно, в соответствии с топологией, чтобы не создавать петель и не терять префиксы. Зачем нам здесь RR? Для реализации Kompella VPLS.
Для построения транспортных MPLS-тунелей используем RSVP-TE. Сможем более гибко управлять прохождением VPN-трафика, настроить балансировку.
Что и с чем будем объединять через L2:
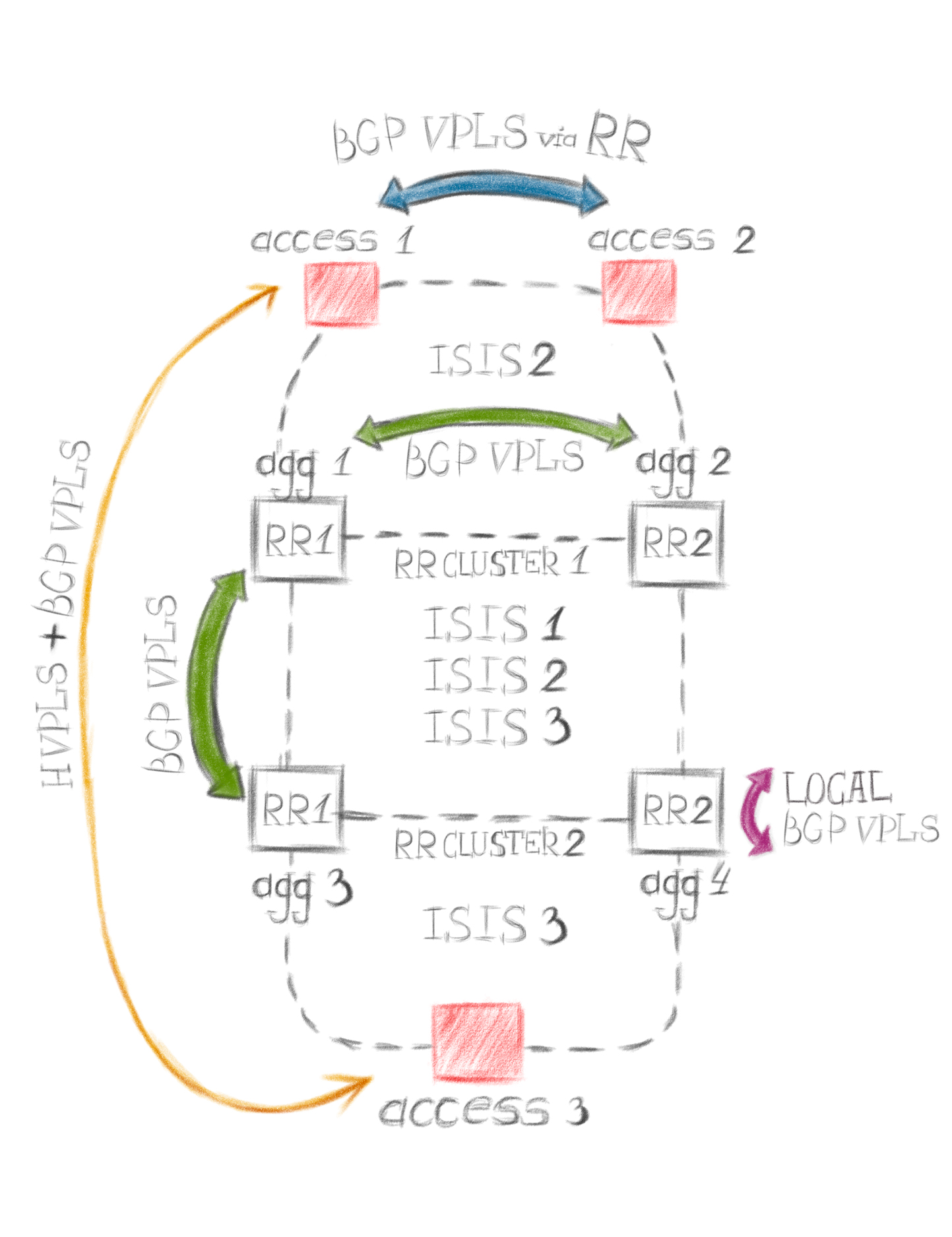
Это та же самая топология. Стрелки указывают на устройства, между которыми мы будем “строить” vpls. Каждый цвет - это отдельный сервис, отдельный vpls-домен. Например, зеленый - настроим первым, между agg 1, agg 2, agg 3, подключим к ним любые хосты и проверим.
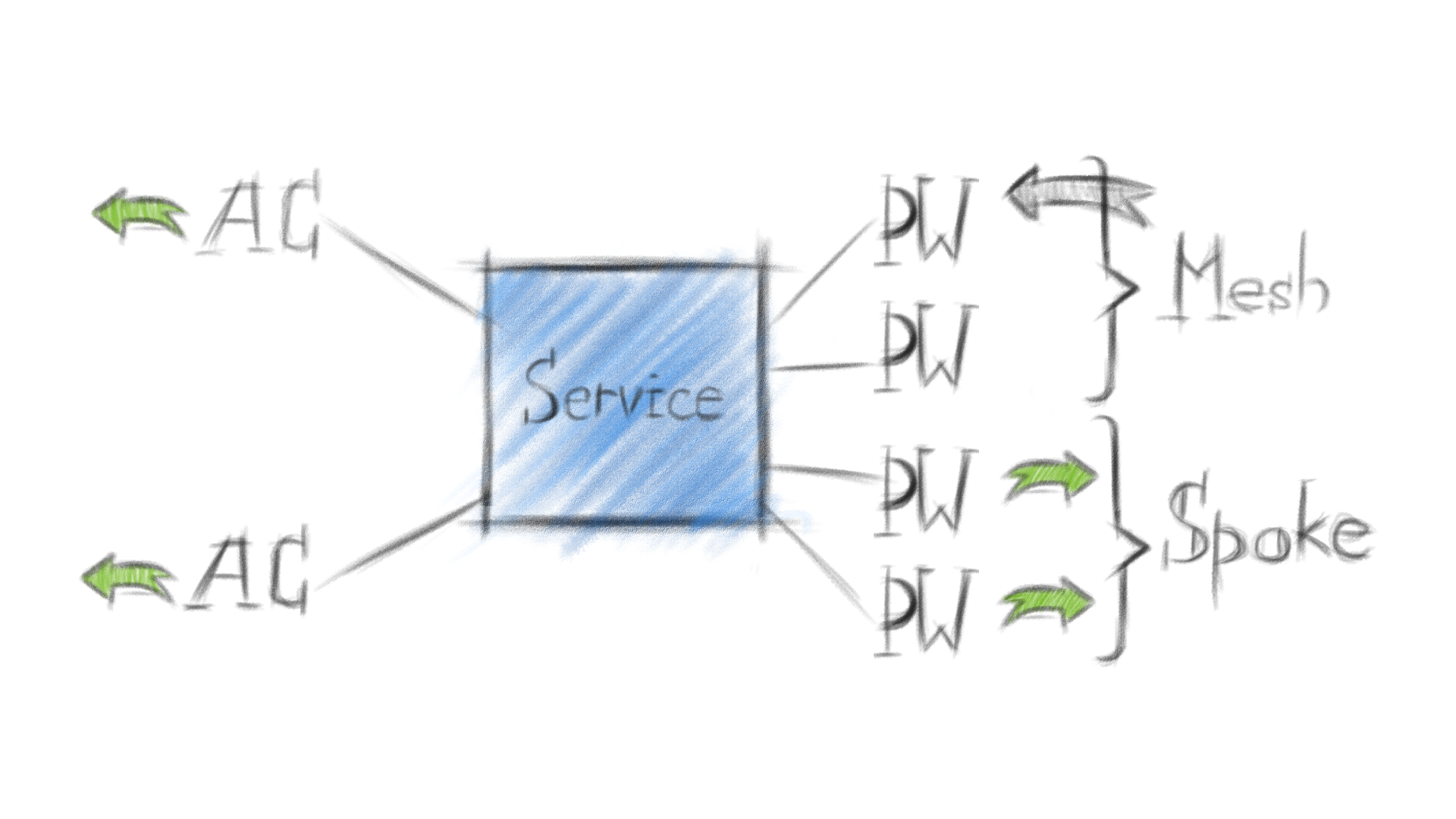
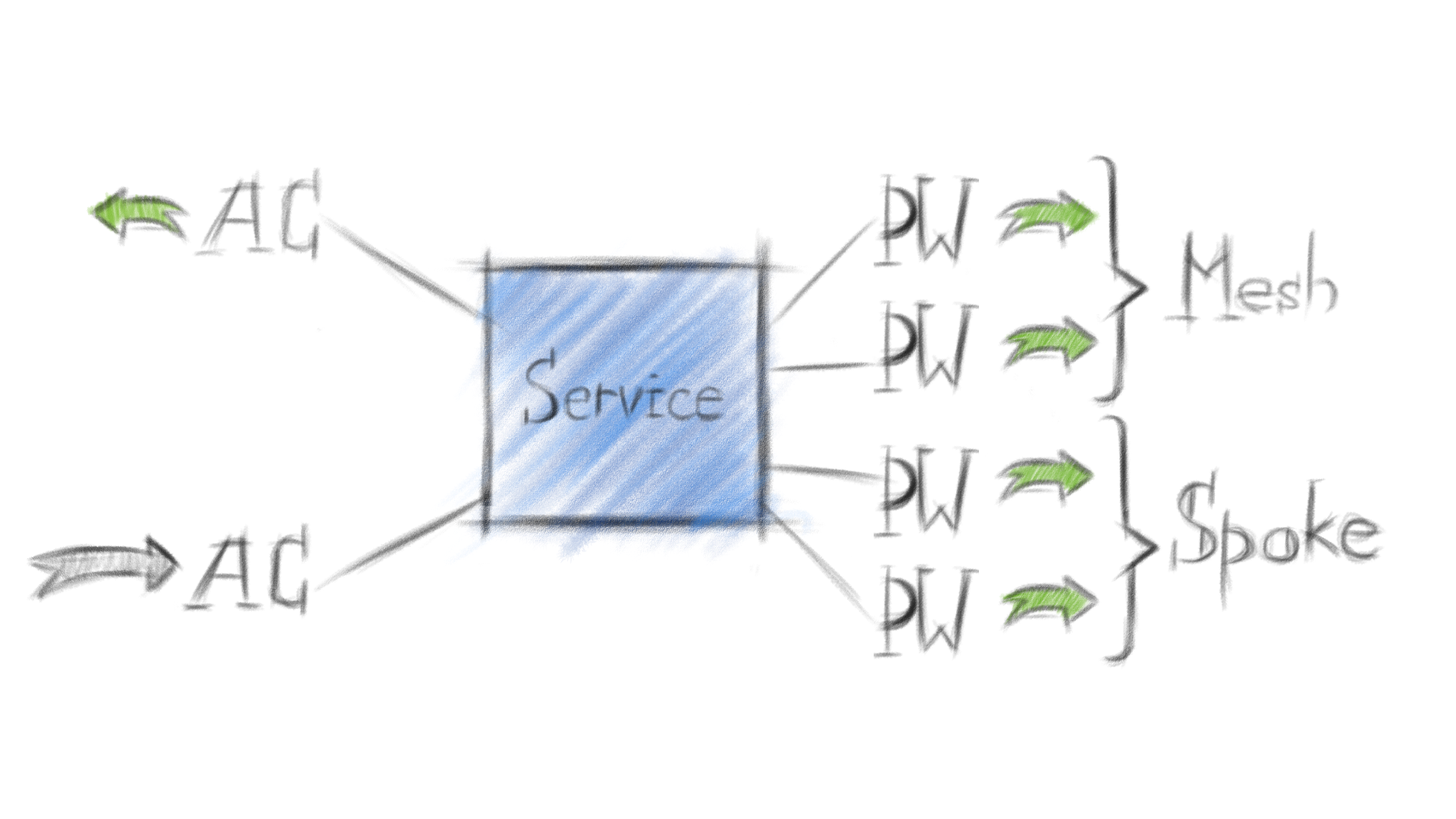
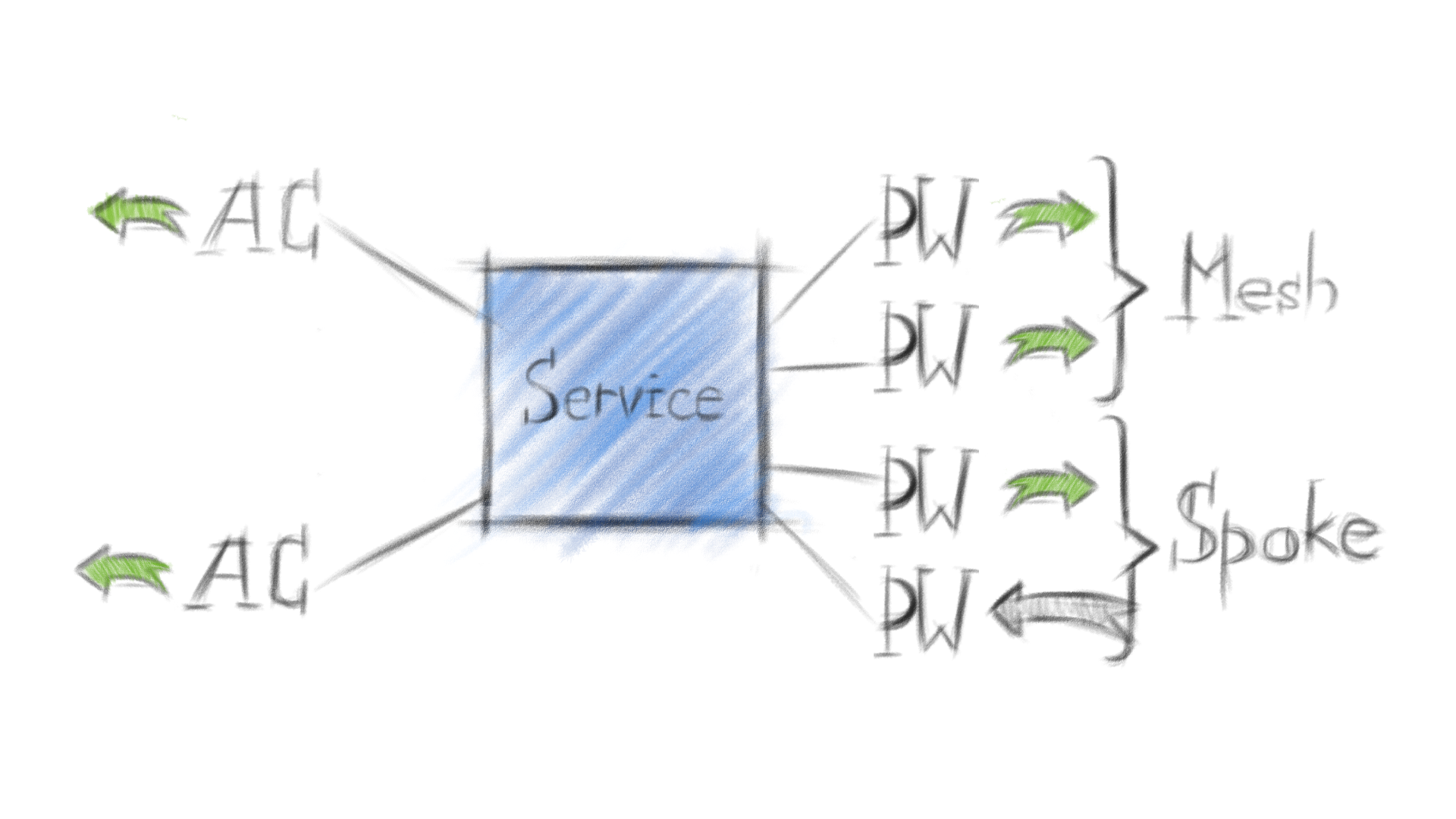
Принципы распространения трафика в VPLS:
картинки, чуть ниже, показывают только VPLS Data Plane, т.е. передачу пользовательского трафика на устройстве-участнике VPLS домена. И это важно.
AC - attached circuit, пользовательский интерфейс на PE-устройстве, принадлежит определенному vsi.
VSI - virtual switching instance, виртуальный коммутатор на PE, VPLS-домен. На Cisco - VFI.
PW - pseudowire, сервисный туннель или виртуальный провод между PE.
Подготовим ISIS и развернем RSVP-TE (актуально для каждого устройства):
isis 1
is-level level-2
cost-style wide # по умолчанию, narrow, от 1 до 63. Для построения LSP MPLS TE и передаче tag, нужно переключиться на wide
bfd all-interfaces enable # включаем динамические bfd для ISIS
bfd all-interfaces min-tx-interval 100 min-rx-interval 100
auto-cost enable # заставляет пересчитать метрику на ISIS-интерфейсах при изменении (например, с narrow на wide)
network-entity 49.0001.0100.0100.0001.00 # net-заголовок для ISIS
is-name agg-1
traffic-eng level-2 # включаем поддержку TE
frr # ну и добавим механизм быстрого перестроения routing table для ISIS
loop-free-alternate level-1
loop-free-alternate level-2
По аналогии настроим еще 2 ISIS instance:
isis 2
is-level level-2
cost-style wide
bfd all-interfaces enable
bfd all-interfaces min-tx-interval 100 min-rx-interval 100
auto-cost enable
network-entity 49.0002.0100.0100.0001.00
is-name agg-1
import-route direct route-policy loopback0-isis # политику описывать не буду, но мы импортируем адреса Lo0 из isis1, так будет удобнее
traffic-eng level-2
frr
loop-free-alternate level-1
loop-free-alternate level-2
isis 3
is-level level-2
cost-style wide
bfd all-interfaces enable
bfd all-interfaces min-tx-interval 100 min-rx-interval 100
auto-cost enable
network-entity 49.0003.0100.0100.0001.00
is-name agg-1
import-route direct tag 3 route-policy loopback0-isis
traffic-eng level-2
frr
loop-free-alternate level-1
loop-free-alternate level-2
Настроим MPLS RSVP TE (на примере agg-1):
mpls lsr-id 10.1.0.1 # обязательно для работы MPLS
#
mpls
mpls te
mpls te auto-frr # работу frr можно увидеть, запустив команду - display mpls te tunnel-interface auto-bypass-tunnel
mpls rsvp-te
mpls te bfd enable # включим динамические bfd
mpls rsvp-te bfd all-interfaces enable
mpls rsvp-te bfd all-interfaces min-tx-interval 100 min-rx-interval 100
mpls te cspf # включаем механизм CSPF
lsp-trigger all # для построения LSP берем как статические, так и IGP-маршруты
Пример настройки интерфейсов (ISIS + MPLS RSVP TE):
interface Ethernet1/0/0
undo shutdown
ip address 10.1.2.1 255.255.255.252
isis enable 1
isis circuit-type p2p # исключаем DIS в ISIS, оставляем только p2p-соединения
isis circuit-level level-2 # все соединения level-2, уже говорили об этом
mpls
mpls te
mpls te auto-frr self-adapting # недостаточно глобально включить auto-frr для MPLS TE, необходимо добавить настройку на интерфейс
mpls rsvp-te
#
interface Ethernet1/0/0.2
vlan-type dot1q 2
ip address 10.1.2.5 255.255.255.252
isis enable 2
isis circuit-type p2p
isis circuit-level level-2
mpls
mpls te
mpls te auto-frr self-adapting
mpls rsvp-te
#
interface Ethernet1/0/0.3
vlan-type dot1q 3
ip address 10.1.2.9 255.255.255.252
isis enable 3
isis circuit-type p2p
isis circuit-level level-2
mpls
mpls te
mpls te auto-frr self-adapting
mpls rsvp-te
Транспортный LSP для VPLS
Мы можем передавать трафик разных vsi по разным транспортным LSP. Для этого в vsi существуют tnl-policy.
Настроим tnl-policy, которая позволит строить VPLS поверх RSVP-TE туннелей. Без нее будет работать только с LDP в качестве транспорта:
tunnel-policy policy1
tunnel select-seq cr-lsp lsp load-balance-number 1
В нашем случае, мы используем политику, в которой указан приоритет для различных типов туннелей (возьмем статические cr-lsp и динамические RSVP TE lsp). Здесь же могут быть gre, bgp, ldp, sr-lsp или их mix. Это Tunnel type prioritizing policy. Здесь же можно настроить балансировку VPN-трафика поверх выбранных ранее типов туннелей. Используем load-balance-number 1, где 1 - число туннелей, используемых для балансировки. 1 - т.к. между РЕ у нас всего по одному туннелю. Можно указать от 1 до 64.
Если же использовать несколько туннелей до одного и того же LSR, то можно привязать VPN-трафик к определенному транспортному туннелю. Например, такой политикой:
tunnel-policy policy1
tunnel binding destination 10.1.0.1 te Tunnel131
tunnel binding destination 10.1.0.2 te Tunnel132
Это уже Tunnel binding policy. Для RSVP туннеля нужно также разрешить привязку командой mpls te reserved-for-binding.
Это то, что касается путей прохождения VPN-трафика. Что касается самих TE туннелей, то ими тоже можно управлять. Например, с помощью ERO (Explicit Route Object, в Huawei - Explicit-path) или Affinity. Настроим hot-standby. Сперва, ERO:
explicit-path main # основной LSP должен обязательно проходить через 10.1.0.2
10.1.0.2
explicit-path backup # резервный LSP должен обязательно проходить через 10.1.0.3 и 10.1.0.4
10.1.0.3
10.1.0.4
Теперь туннель:
interface Tunnel0/1/111
description test_tunnel
tunnel-protocol mpls te
mpls te record-route label # включаем механизм сохранения меток для резервного туннеля и корректной работы FRR
mpls te fast-reroute # включаем механизм FRR для мгновенного переключения на резервный туннель
ip address unnumbered interface LoopBack0 # используем source-адрес на Loo0-интерфейсе
destination 10.1.0.2
mpls te tunnel-id 1111 # произвольный id
mpls te commit # разрешаем изменения
mpls te path explicit-path main # указываем основной путь для туннеля
mpls te path explicit-path backup secondary # указываем резервный путь для туннеля
mpls te backup hot-standby mode revertive wtr 30 # время переключения на основной LSP после восстановления
mpls te backup ordinary best-effort # будем пытататься строить best effort LSP только если основной и резервный LSP будут не доступны
mpls te backup hot-standby overlap-path # основной и резервный LSP могут частитчно пересекаться
mpls te backup frr-in-use # разрешаем механизм FRR при переключении на резервный LSP
Теперь, Affinity:
здесь кратко. С помощью этого механизма можно разрешать или запрещать определенные типы LSP через интерфейс. Типы LSP могут быть такими: HSB+PR, HSB only, BE+HSB+PR и т.п. Каждый тип принадлежит административной группе, от номера которой зависит какие типы туннелей разрешены или запрещены при прохождении через интерфейс. Выглядит так:
interface GigabitEthernet4/1/1
mpls te link administrative group 111 # разрешим BE+HSB+PR
Для туннеля задаем affinity бит:
interface Tunnel0/1/111
mpls te affinity property 1 mask 1
mpls te affinity property 10 mask 10 secondary
mpls te affinity property 100 mask 100 best-effort
Это может быть полезно, когда вы хотите строить через арендованный или самый ненадежный ликн только best-effort.
Теперь VPLS
1. agg-1 <-> agg-2 <-> agg-3:
Объединим в один vpls-домен интерфейсы на agg-1, agg-2 и agg-3
Настроим vsi.
agg-1:
vsi test
mac-withdraw enable # чистим mac-адреса в vsi в случае падения AC
pwsignal bgp # используем bgp для распространения сервисных меток и поиска соседей
route-distinguisher 10.1.0.1:1 # каждый BGP Update должен быть уникален в пределах РЕ, для разных РЕ это правило не действует
vpn-target 65001:200001 import-extcommunity # управляем импортом и экспортом BGP Update в/из нужный/нужного vsi
vpn-target 65001:200001 export-extcommunity
site 1 range 10 default-offset 0 # site id должен различать для разных РЕ одного vsi (одного vpls-домена). Site id на локальном PE должен быть меньше чем range (по умолчанию, 10) + default offset (смещение), но больше либо равен значению default offset (по умолчанию, 0).
Например, берем VPLS домен на 20 устройств (один vsi на 20 РЕ), указываем значения site от 1 до 19 (должны отличаться на каждом РЕ, входящем в vsi). Site для разных vsi на локальном РЕ могут совпадать.
encapsulation ethernet # тип инкапсуляции трафика, после прохождения через AC-интерфейс.
Для ethernet:
- если на АС пришел фрейм с тегом, тег будет удален, фрейм передан дальше уже без тега
- если на АС пришел фрем без тега, то он будет передан дальше
Для vlan (режим по умолчанию):
- если на АС пришел фрейм без тега, тег будет добавлен
- если на АС пришел фрейм с тегом, он будет передан дальше
tnl-policy policy1 # та самая политика, регулирующая прохождение трафика через транспортные туннели
По аналогии для остальных agg, участвующих в VPLS-домене:
agg-2:
vsi test
pwsignal bgp
route-distinguisher 10.1.0.2:1
vpn-target 65001:200001 import-extcommunity
vpn-target 65001:200001 export-extcommunity
site 2 range 10 default-offset 0
encapsulation ethernet
tnl-policy policy1
agg-3:
vsi test
mac-withdraw enable
pwsignal bgp
route-distinguisher 10.10.0.1:1
vpn-target 65001:200001 import-extcommunity
vpn-target 65001:200001 export-extcommunity
site 3 range 10 default-offset 0
encapsulation ethernet
tnl-policy policy1
Теперь настроим отдельную l2vpn-ad-family в BGP для Kompella VPLS. Сразу определимся с соседями. Между всеми RR настроим полносвязную топологию, а на всех RR-клиентах понадобится только соседство с RR-кластером (RR будут передавать апдейты всем non-RR-клиентам, EBGP-соседям и, разумеется, RR-клиентам). BGP Update будут получать все устройства, с которыми поднято соседство на RR, но префикс (а это RD, RT, номер узла в VPLS домене (site), блок меток, vpn id, смещение) будут принимать только те РЕ, vsi которых содержат одинаковые RT. За счет RR мы реализуем механизм автоматического поиска соседей, Auto-Discovery, в Kompella VPLS. Это все Control Plane.
Теперь про Data Plane. Поскольку это L2-сервис, важно, чтобы mac-адреса были изучены правильно, и пользовательский кадр передавался только между нужными РЕ. А следовательно, каждый РЕ, участник VPLS-домена, должен иметь свою уникальную метку (здесь не как в L3VPN, общая метка для всех участников VRF). Поэтому вместе с Auto-Discovery в том же самом BGP Update (в секциях NLRI и Communities) РЕ получают всю необходимую для вычисления уникальных меток информацию. Это красиво.
vsi настроили, настроим отдельную l2vpn-ad-family в BGP:
agg-1:
bgp 65001 # произвольный as-number из "серого" диапазона
router-id 10.1.0.1 # передается в BGP Open, должен быть уникален для установления соседства
graceful-restart # RFC4724. Маршрутизатор продолжает передавать BGP-трафик при перезагрузке BGP-процесса или самого маршрутизатора
peer 10.1.0.2 as-number 65001 # настроим iBGP соседей
peer 10.1.0.2 description RR2
peer 10.1.0.2 connect-interface LoopBack0 # для установления соседства использовать адрес Lo0
group ACCESS_2 internal # создаем группу и упрощаем настройку BGP, применяя одинаковые настройки для группы iBGP-соседей
peer ACCESS_2 connect-interface LoopBack0
peer 10.2.0.1 as-number 65001 # access-1 маршрутизатор
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 as-number 65001 # access-2 маршрутизатор
peer 10.2.0.2 group ACCESS_1
group RR-2 internal # создадим и настроим соседство со вторым RR-кластером (agg-3 и agg-4)
peer RR-2 connect-interface LoopBack0
peer 10.10.0.1 as-number 65001
peer 10.10.0.1 group RR-2
peer 10.10.0.2 as-number 65001
peer 10.10.0.2 group RR-2
#
ipv4-family unicast # настраиваем ipv4-family. Здесь все, что относится к базовой настройке BGP
undo synchronization # отключаем синхронизацию BGP с IGP. На NE40E отключена, по умолчанию
reflector cluster-id 65001 # настроим RR-кластер между agg-1 и agg-2. Для исключения петель при передаче маршрутов в кластере и между кластерами в BGP Update есть поле CLUSTER_LIST, куда добавляется cluster-id. Если маршрутизатор получит BGP Update, где указан его cluster-id, такой Update будет отброшен.
reflect change-path-attribute # разрешаем на RR изменять BGP-аттрибуты с помощью route-policy (route-map в cisco). По умолчанию запрещено для всех отзеркаленных маршрутов.
aggregate 10.1.0.0 255.255.255.0 # разрешаем суммаризацию в BGP для указанных префиксов
aggregate 192.168.32.0 255.255.255.0
peer 10.1.0.2 enable
peer ACCESS_2 enable
peer ACCESS_2 next-hop-local # заменяем для BGP Update в поле Path attributes адрес NEXT_HOP на адрес маршрутизатора. iBGP указывает на точку выхода из AS, а AS у нас одинаковый, поэтому важно следит за адресом next-hop при передаче маршрутной информации
peer 10.2.0.1 enable # устанавливаем соседство с access-1 и access-2 маршрутизаторами, добавляем их в группу
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 enable
peer 10.2.0.2 group ACCESS_1
peer RR-2 enable # устанавливаем соседство с agg-3 и agg-4 (RR-cluster 2) маршрутизаторами, добавляем их в группу
peer RR-2 next-hop-local # настраиваем адрес next-hop разом, для всей группы соседей
peer 10.10.0.1 enable
peer 10.10.0.1 group RR-2
peer 10.10.0.2 enable
peer 10.10.0.2 group RR-2
#
l2vpn-ad-family # настроим family для Kompella VPLS
reflector cluster-id 65001 # формируем RR-кластер из agg-1 и agg-2, так было задумано
reflect change-path-attribute # разрешаем изменять BGP-аттрибуты на RR
policy vpn-target # разрешаем фильтрацию vpn-маршрутов в BGP (аналогично включается и для других family, например vpnv4)
peer 10.10.0.1 enable
peer 10.10.0.1 signaling vpls # включаем BGP signaling для работы Kompella VPLS
peer ACCESS_1 enable # хотя здесь речь идет о передаче BGP Update только между agg-1(2,3), настроим заранее RR-клиентов (access-1 и access-2)
peer ACCESS_2 reflect-client
peer ACCESS_2 signaling vpls
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 enable
peer 10.2.0.2 group ACCESS_1
agg-2:
bgp 65001
router-id 10.1.0.2
graceful-restart
peer 10.1.0.1 as-number 65001
peer 10.1.0.1 description RR1
peer 10.1.0.1 connect-interface LoopBack0
group ACCESS_2 internal
peer ACCESS_2 connect-interface LoopBack0
peer 10.2.0.1 as-number 65001
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 as-number 65001
peer 10.2.0.2 group ACCESS_1
group RR-2 internal
peer RR-2 connect-interface LoopBack0
peer 10.10.0.1 as-number 65001
peer 10.10.0.1 group RR-2
peer 10.10.0.2 as-number 65001
peer 10.10.0.2 group RR-2
#
ipv4-family unicast
undo synchronization
reflector cluster-id 65001
reflect change-path-attribute
aggregate 10.1.0.0 255.255.255.0
aggregate 192.168.32.0 255.255.255.0
peer 10.1.0.1 enable
peer ACCESS_1 enable
peer ACCESS_1 next-hop-local
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 enable
peer 10.2.0.2 group ACCESS_1
peer RR-2 enable
peer RR-2 next-hop-local
peer 10.10.0.1 enable
peer 10.10.0.1 group RR-2
peer 10.10.0.2 enable
peer 10.10.0.2 group RR-2
#
l2vpn-ad-family
reflector cluster-id 65001
reflect change-path-attribute
policy vpn-target
peer 10.10.0.1 enable
peer 10.10.0.1 signaling vpls
peer ACCESS_1 enable # хотя здесь речь идет о передаче BGP Update только между agg-1(2,3), настроим заранее RR-клиентов (access-1 и access-2)
peer ACCESS_1 reflect-client
peer ACCESS_1 signaling vpls
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 enable
peer 10.2.0.2 group ACCESS_1
agg-3:
bgp 65001
graceful-restart
peer 10.10.0.2 as-number 65001
peer 10.10.0.2 description RR-2
peer 10.10.0.2 connect-interface LoopBack0
group ACCESS_2 internal
peer ACCESS_2 connect-interface LoopBack0
peer 10.3.0.1 as-number 65001 # заранее настроим соседство с access-3 маршрутизатором
peer 10.3.0.1 group ACCESS_2
group RR-1 internal # создадим группу RR-1 (agg-1 + agg-2) и поднимем соседство между RR-кластерами. Здесь кстати должен быть full-mesh
peer RR-1 connect-interface LoopBack0
peer 10.1.0.1 as-number 65001
peer 10.1.0.1 group RR-1
peer 10.1.0.2 as-number 65001
peer 10.1.0.2 group RR-1
#
ipv4-family unicast
undo synchronization
reflector cluster-id 65002 # должен быть уникален относительно других RR-кластеров
reflect change-path-attribute
aggregate 10.10.0.0 255.255.255.0
aggregate 192.168.32.0 255.255.255.0
peer 10.10.0.2 enable
peer ACCESS_2 enable
peer ACCESS_2 next-hop-local
peer 10.3.0.1 enable
peer 10.3.0.1 group ACCESS_2
peer RR-1 enable
peer RR-1 next-hop-local
peer 10.1.0.1 enable
peer 10.1.0.1 group RR-1
peer 10.1.0.2 enable
peer 10.1.0.2 group RR-1
#
l2vpn-ad-family
reflector cluster-id 65002 # формируем RR-кластер из agg-3 и agg-4, все по схеме
reflect change-path-attribute
policy vpn-target
peer 10.1.0.1 enable
peer 10.1.0.1 signaling vpls
peer 10.1.0.2 enable
peer 10.1.0.2 signaling vpls
peer ACCESS_2 enable # хотя здесь речь идет о передаче BGP Update только между agg-1(2,3), настроим заранее RR-клиентов (access-3)
peer ACCESS_2 reflect-client
peer ACCESS_2 signaling vpls
peer 10.3.0.1 enable
peer 10.3.0.1 group ACCESS_2
После всех настроек BGP Update между 10.1.0.1 и 10.1.0.2 будет выглядеть так:
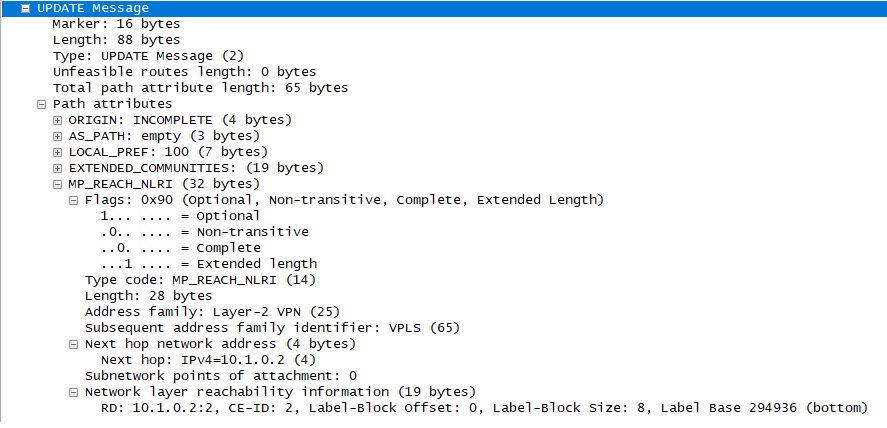
Здесь адрес Next hop - адрес соседа передающего сервисную метку для vsi test, настроенного ранее. В секции NLRI (Network layer reachability information) видим блок меток для расчета уникальной сервисной метки (для того же vsi test)
Подключим хосты, проверим работу vpls-сегмента (уже знакомая картинка из eNSP):
Настроим интерфейсы Ethernet1/0/5 на agg-1,2,3:
Interface Ethernet1/0/5
l2 binding vsi test
На PC1,2,3 настроим статическую адресацию, возьмем адреса 192.168.0.1,2,3/24.
Проверим, например, на agg-3 настроенный L2-сервис: Для начала, проверим транспортные RSVP-TE туннели:
<agg-3>display tunnel-info all
Tunnel ID Type Destination
Status
--------------------------------------------------------------------------------
0x000000000300000001 te 10.1.0.1
UP
0x000000000300000002 te 10.1.0.2
UP
0x000000000300000003 te 10.10.0.2
UP
Теперь проверим vsi:
<agg-3>display vsi
Total VSI number is 1, 1 is up, 0 is down, 0 is LDP mode, 1 is BGP mode, 0 is BG
PAD mode, 0 is mixed mode, 0 is unspecified mode
--------------------------------------------------------------------------
Vsi Mem PW Mac Encap Mtu Vsi
Name Disc Type Learn Type Value State
--------------------------------------------------------------------------
test -- bgp unqualify ethernet 1500 up
Смотрим на vsi state. Для того,чтобы vsi на локальном устройстве был up:
- на vsi-соседях должен совпадать mtu. Можно отключить согласование mtu командной mtu-negotiate disable;
- AC-интерфейс должен быть в up. Обойти можно командной ignore-ac-state;
- транспортный туннель должен быть up
Если vsi не поднимается, то причину можно найти посмотрев детальную конфигурацию:
display vsi test verbose
<agg-3>display vsi name test ver
***VSI Name : test
Work Mode : normal
Administrator VSI : no
Isolate Spoken : disable
VSI Index : 1
PW Signaling : bgp
Member Discovery Style : --
Bridge-domain Mode : disable
** PW MAC Learn Style : unqualify **
** Encapsulation Type : ethernet **
** MTU : 1500 **
Diffserv Mode : uniform
Service Class : --
Color : --
DomainId : 255
Domain Name :
Tunnel Policy Name : policy1
Ignore AcState : disable
P2P VSI : disable
VSI MAC-WITHDRAW : mac-withdraw Enable
Multicast Fast Switch : disable
Create Time : 6 days, 21 hours, 29 minutes, 0 seconds
** VSI State : up **
Resource Status : --
BGP RD : 10.1.0.2:1
SiteID/Range/Offset : 1/10/0
Import vpn target : 65001:200001
Export vpn target : 65001:200001
** Remote Label Block : 294928/8/0 294928/8/0
Local Label Block : 0/294928/8/0 **
** Interface Name : Ethernet1/0/5
State : up **
Ac Block State : unblocked
Access Port : false
Last Up Time : 2019/12/18 16:59:15
Total Up Time : 6 days, 21 hours, 25 minutes, 32 seconds
**PW Information:
*Peer Ip Address : 10.1.0.2
PW State : up
Local VC Label : 294930
Remote VC Label : 294929
PW Type : label
Tunnel ID : 0x000000000300000002
Broadcast Tunnel ID : --
Broad BackupTunnel ID : --
Ckey : 95874
Nkey : 50332038
Main PW Token : 0x0
Slave PW Token : 0x0
Tnl Type : te
OutInterface : --
Backup OutInterface : --
Stp Enable : 0
Mac Flapping : 0
Monitor Group Name : --
PW Last Up Time : 2019/12/25 14:50:12
PW Total Up Time : 0 days, 0 hours, 0 minutes, 38 seconds
*Peer Ip Address : 10.1.0.1
** PW State : up **
Local VC Label : 294931
Remote VC Label : 294929
PW Type : label
** Tunnel ID : 0x000000000300000001 **
Broadcast Tunnel ID : --
Broad BackupTunnel ID : --
Ckey : 96001
Nkey : 50332039
Main PW Token : 0x0
Slave PW Token : 0x0
Tnl Type : te
OutInterface : --
Backup OutInterface : --
Stp Enable : 0
Mac Flapping : 0
Monitor Group Name : --
PW Last Up Time : 2019/12/25 14:49:52
PW Total Up Time : 0 days, 0 hours, 0 minutes, 48 seconds
Поля, на которые следует обратить внимание, выделены **. Из интересного здесь “PW MAC Learn Style” и “Encapsulation Type”. Для первого доступны значения qualify и unqualify. Qualify - когда РЕ изучает mac-адреса для конкретных vlan отдельно. В unqualify - общий broadcast домен для всех vlan. Касаемо Encapsulation Type, влияет на инкапсуляцию трафика, проходящего через AC, бывает или vlan (по умолчанию), или ethernet, уже писал об этом выше, повторим и здесь.
Для ethernet:
- если на АС пришел фрейм с тегом, тег будет удален, фрейм передан дальше уже без тега
- если на АС пришел фрем без тега, то он будет передан дальше
Для vlan (режим по умолчанию):
- если на АС пришел фрейм без тега, тег будет добавлен
- если на АС пришел фрейм с тегом, он будет передан дальше tnl-policy policy1 # та самая политика, регулирующая прохождение трафика через транспортные туннели
Поле “Tunnel ID” должно быть не пустым, это означает, что PW знает, какой транспортный туннель необходимо использовать для пользовательского трафика.
Итак, с vsi все ок. Теперь, проверим состояние VC. Грубо говоря, VC (virtual circuit) - это путь, по которому будет передаваться пользовательский трафик. VC может быть не один, их может быть много. Это уже PW (pseudowire).
<agg-3>display vpls connection
2 total connections,
connections: 2 up, 0 ldp, 2 bgp, 0 bgpad
VSI Name: test Signaling: bgp
SiteID RD PeerAddr InLabel OutLabel VCState
2 10.10.0.1:1 10.1.0.2 294930 294929 up
3 10.1.0.1:1 10.1.0.1 294931 294929 up
Помимо состояния VC, здесь же видим и выданные соседями по vsi сервисные метки.
Ничего не мешает нам запустить icmp между любыми PC, но сделаем это позже. Посмотрим, каким LSP пойдет трафик:
<agg-3>display vsi pw out-interface
Total: 1
--------------------------------------------------------------------------------
Vsi Name peer vcid interface
--------------------------------------------------------------------------------
test 10.1.0.1 3 Tunnel0/7/111
Например, до 10.1.0.1 пользовательский трафик пойдет через Tunnel0/7/111 (номер интерфейса здесь произвольный). Посмотрим LSP для этого туннеля:
<agg-3>display mpls te tunnel path
Tunnel Interface Name : Tunnel0/7/111
Lsp ID : 10.10.0.1 :7111 :62214
Hop Information
Hop 0 192.168.32.2
Hop 1 192.168.32.1 Label 3
Hop 2 10.1.0.1 Label 3
Видим все хопы, через которые пойдет пользовательский трафик. А еще видим 3 метку, это PHP, он включен, по умолчанию. Здесь, конечно, будет информация по всем туннелям, я оставил только интересующий нас. С учетом включенного frr для mpls te, в выводе будут еще AutoTunnel.
Для этой же задачи можно воспользоваться командой tracert vpls.
Проверим, что пользовательские интерфейсы, действительно, привязаны к vsi test:
<agg-3>display vsi service test
Total: 1
Code: AS(Admin Status), PS(Physical Status)
--------------------------------------------------------------------------------
Interface/Bridge-domain Vsi Name AS PS
--------------------------------------------------------------------------------
Ethernet1/0/5 test up up
Теперь, PC1,2,3 будут обмениваться icmp.
Посмотрим на пользовательские mac-address:
<agg-3>display mac-address vsi test
MAC address table of slot 1:
-------------------------------------------------------------------------------
MAC Address VLAN/BD/ PEVLAN CEVLAN Port/Peerip Type LSP/LSR-ID
VSI/SI/EVPN MAC-Tunnel
-------------------------------------------------------------------------------
5489-980e-7881 test - - Eth1/0/5 dynamic 1/0
5489-98ee-1e09 test 3 - Eth1/0/2.3 dynamic 1/384
-------------------------------------------------------------------------------
Total matching items on slot 1 displayed = 2
В таблице для удаленного устройства (5489-98ee-1e09) мы сразу видим не туннельный интерфейс, а конкретный физический (Eth1/0/2.3).
Запустим ping между PC1 и PC2 и откроем wireshark на интерфейсе Ethernet 1/0/3 agg-1:
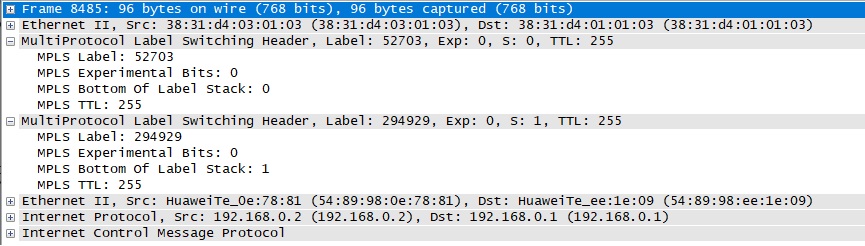
Видим стек меток. Метка 294929 - сервисная метка, с которой пакет будет передан на agg-2. На agg-1 будет выполнена процедура PHP, на agg-2 будет передан только один заголовок MPLS, с сервисной меткой.
2. access-3 <-> access-1
Здесь сложнее, т.к. access-3 и access-1(2) принадлежат разным isis-инстансам. По этой же причине построить PW между устройствами, указав их в l2vpn-ad-family в качестве соседей, не получится. Да и не нужно, хотя бы, по следующим причинам:
- access-маршрутизаторы не связаны “прямыми” линками, а общаются между собой через agg и никак иначе
- можно указать agg в качестве соседей в l2vpn-ad-family. Но split horizon не позволит передать пользовательский трафик дальше agg (смотри выше, в “Принципы распространения трафика в VPLS”)
- можно отбросить вопрос масштабируемости и добавить все access в общий isis-инстанс. В реальной жизни число access-маршрутизаторов будет больше 3, поддерживать full-mesh, при этом, будет непросто, не оптимально и не надо так
На картинке “Принципы распространения трафика в VPLS” есть spoke-устройства. Это H-VPLS, описанный в RFC4762. Придуман, чтобы упростить жизнь с VPLS Martini-mode, но поможет решить и нашу проблему с передачей пользовательского трафика между access-3 и access-1.
Выберем кластер agg, через которые будет проходить PW. Возьмем по наименьшим адресам Lo0, т.е. agg-1 и agg-2.
Пример конфигурации (включая полную конфигурацию bgp и уже, практически, без комментариев):
agg-1:
mpls l2vpn
vsi test1
pwsignal bgp
route-distinguisher 10.1.0.1:2
vpn-target 65001:200002 import-extcommunity
vpn-target 65001:200002 export-extcommunity
site 1 range 10 default-offset 0
tnl-policy policy1
bgp 65001
router-id 10.1.0.1
graceful-restart
peer 10.1.0.2 as-number 65001
peer 10.1.0.2 description agg-2
peer 10.1.0.2 connect-interface LoopBack0
group RR-2 internal
peer RR-2 connect-interface LoopBack0
peer 10.10.0.1 as-number 65001
peer 10.10.0.1 group RR-2
peer 10.10.0.2 as-number 65001
peer 10.10.0.2 group RR-2
group ACCESS_1 internal
peer ACCESS_1 connect-interface LoopBack0
peer 10.2.0.1 as-number 65001
peer 10.2.0.1 group ACCESS_1
#
ipv4-family unicast
undo synchronization
reflector cluster-id 65001
reflect change-path-attribute
peer 10.1.0.2 enable
peer RR-2 enable
peer RR-2 next-hop-local
peer 10.10.0.1 enable
peer 10.10.0.1 group RR-2
peer 10.10.0.2 enable
peer 10.10.0.2 group RR-2
peer ACCESS_1 enable
peer ACCESS_1 next-hop-local # опционально для ipv4-family. Только, если желаете, чтобы трафик для ipv4 всегда "ходил" через RR
peer ACCESS_1 reflect-client
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
#
l2vpn-ad-family
reflector cluster-id 65001 # RR-кластер из agg-1 и agg-2, всё согласно схеме
reflect change-path-attribute
policy vpn-target
peer ACCESS_1 enable
peer ACCESS_1 signaling vpls
peer ACCESS_1 reflect-client
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
agg-2:
mpls l2vpn
vsi test1
pwsignal bgp
route-distinguisher 10.1.0.2:2
vpn-target 65001:200002 import-extcommunity
vpn-target 65001:200002 export-extcommunity
site 2 range 10 default-offset 0
tnl-policy policy1
bgp 65001
router-id 10.1.0.2
graceful-restart
peer 10.1.0.1 as-number 65001
peer 10.1.0.1 description agg-1
peer 10.1.0.1 connect-interface LoopBack0
group RR-2 internal
peer RR-2 connect-interface LoopBack0
peer 10.10.0.1 as-number 65001
peer 10.10.0.1 group RR-2
peer 10.10.0.2 as-number 65001
peer 10.10.0.2 group RR-2
group ACCESS_1 internal
peer ACCESS_1 connect-interface LoopBack0
peer 10.2.0.1 as-number 65001
peer 10.2.0.1 group ACCESS_1
#
ipv4-family unicast
undo synchronization
reflector cluster-id 65001
reflect change-path-attribute
peer 10.2.0.1 enable
peer RR-2 enable
peer RR-2 next-hop-local
peer 10.10.0.1 enable
peer 10.10.0.1 group RR-2
peer 10.10.0.2 enable
peer 10.10.0.2 group RR-2
peer ACCESS_1 enable
peer ACCESS_1 next-hop-local
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
#
l2vpn-ad-family
reflector cluster-id 65001 # RR-кластер из agg-1 и agg-2, всё согласно схеме
reflect change-path-attribute
policy vpn-target
peer ACCESS_1 enable
peer ACCESS_1 signaling vpls
peer ACCESS_1 reflect-client
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
access-1 (RR-client):
mpls l2vpn
vsi test1
pwsignal bgp
route-distinguisher 10.2.0.1:1
vpn-target 65001:200002 import-extcommunity
vpn-target 65001:200002 export-extcommunity
site 3 range 10 default-offset 0
tnl-policy policy1
bgp 65001
router-id 10.2.0.1
graceful-restart
peer 10.1.0.1 as-number 65001
peer 10.1.0.1 description agg-1
peer 10.1.0.1 connect-interface LoopBack0
peer 10.1.0.2 as-number 65001
peer 10.1.0.2 description agg-2
peer 10.1.0.2 connect-interface LoopBack0
group RR internal
peer RR connect-interface LoopBack0
#
ipv4-family unicast
undo synchronization
peer RR enable
peer RR next-hop-local
peer 10.1.0.1 enable
peer 10.1.0.1 group RR
peer 10.1.0.2 enable
peer 10.1.0.2 group RR
#
l2vpn-ad-family
policy vpn-target
peer 10.1.0.1 enable
peer 10.1.0.1 signaling vpls
peer 10.1.0.2 enable
peer 10.1.0.2 signaling vpls
Настройка Kompella BGP между agg-1(2) и access-1 выполнена. Здесь ничего нового.
С помощью H-VPLS (Martini H-VPLS TLDP) настроим связность с access-3, находящимся в отдельном ISIS домене:
agg-1 (SPOKE-1):
vsi test1
pwsignal ldp
vsi-id 1
peer 10.3.0.1 upe
tnl-policy policy1
agg-2 (SPOKE-2):
vsi test1
pwsignal ldp
vsi-id 1
peer 10.3.0.1 upe
tnl-policy policy1
Настраиваем статический vsi на access-3 (он же H-VPLS node, MTU-s, u-PE):
vsi test1 static
pwsignal ldp
vsi-id 1
peer 10.1.0.1
peer 10.1.0.2
tnl-policy policy1
protect-group test1
protect-mode pw-redundancy master
peer 10.1.0.1 preference 1
peer 10.1.0.2 preference 2
reroute delay 60
Здесь мы используем redundancy mode, т.е. основной PW будет проходить через 10.1.0.1, а 10.1.0.2 будет резервным. Для быстрого переключения на резервный PW настроим статические bfd. Достаточно следить только за основным PW:
access-3:
Static BFD for preference 1 PW:
bfd p1 bind pw vsi test1 peer 10.1.0.1 remote-peer 10.1.0.1 pw-ttl auto-calculate
discriminator local 104
discriminator remote 401
agg-1:
bfd p1 bind pw vsi test1 peer 10.2.0.1 remote-peer 10.2.0.1 pw-ttl auto-calculate
discriminator local 401
discriminator remote 104
Не забываем включить и настроить TLDP (RLDP в Huawei), иначе over mpls te ничего не заработает: access-3:
mpls ldp
mpls ldp remote-peer 10.1.0.1
remote-ip 10.1.0.1
mpls ldp remote-peer 10.1.0.2
remote-ip 10.1.0.2
agg-1(2):
mpls ldp
mpls ldp remote-peer 10.3.0.1
remote-ip 10.3.0.1
3. access-1 <-> access-2:
Все содержащие VPLS-информацию BGP Update сообщения будут передаваться через соответствующий RR-cluster (agg-1 + agg-2). Пример конфигурации:
agg-1:
bgp 65001
router-id 10.1.0.1
graceful-restart
peer 10.1.0.2 as-number 65001
peer 10.1.0.2 description RR-2
peer 10.1.0.2 connect-interface LoopBack0
group ACCESS_1 internal
peer ACCESS_1 connect-interface LoopBack0
peer 10.2.0.1 as-number 65001
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 as-number 65001
peer 10.2.0.2 group ACCESS_1
#
ipv4-family unicast
undo synchronization
reflector cluster-id 65001
reflect change-path-attribute
peer 10.1.0.2 enable
peer ACCESS_1 enable
peer ACCESS_1 next-hop-local
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 enable
peer 10.2.0.2 group ACCESS_1
#
l2vpn-ad-family
reflector cluster-id 65001 # RR-кластер из agg-1 и agg-2, всё согласно схеме
reflect change-path-attribute
policy vpn-target
peer ACCESS_1 enable
peer ACCESS_1 reflect-client
peer ACCESS_1 signaling vpls
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 enable
peer 10.2.0.2 group ACCESS_1
agg-2:
bgp 65001
router-id 10.1.0.2
graceful-restart
peer 10.1.0.1 as-number 65001
peer 10.1.0.1 description RR-1
peer 10.1.0.1 connect-interface LoopBack0
group ACCESS_1 internal
peer ACCESS_1 connect-interface LoopBack0
peer 10.2.0.1 as-number 65001
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 as-number 65001
peer 10.2.0.2 group ACCESS_1
#
ipv4-family unicast
undo synchronization
reflector cluster-id 65001
reflect change-path-attribute
aggregate 10.1.0.0 255.255.255.0
aggregate 192.168.32.0 255.255.255.0
peer 10.1.0.1 enable
peer ACCESS_1 enable
peer ACCESS_1 next-hop-local
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 enable
peer 10.2.0.2 group ACCESS_1
#
l2vpn-ad-family
reflector cluster-id 65001 # RR-кластер из agg-1 и agg-2, всё согласно схеме
reflect change-path-attribute
policy vpn-target
peer ACCESS_1 enable
peer ACCESS_1 reflect-client
peer ACCESS_1 signaling vpls
peer 10.2.0.1 enable
peer 10.2.0.1 group ACCESS_1
peer 10.2.0.2 enable
peer 10.2.0.2 group ACCESS_1
access-1:
bgp 65001
router-id 10.2.0.1
graceful-restart
group RR internal
peer RR connect-interface LoopBack0
peer 10.1.0.1 as-number 65001
peer 10.1.0.1 group RR
peer 10.1.0.2 as-number 65001
peer 10.1.0.2 group RR
#
ipv4-family unicast
undo synchronization
peer RR enable
peer RR next-hop-local
peer 10.1.0.1 enable
peer 10.1.0.1 group RR
peer 10.1.0.2 enable
peer 10.1.0.2 group RR
#
l2vpn-ad-family # соседство устанавливаем только с RR
policy vpn-target
peer 10.1.0.1 enable
peer 10.1.0.1 signaling vpls
peer 10.1.0.2 enable
peer 10.1.0.2 signaling vpls
На agg-1 и agg-2, в секции l2vpn-ad-family, не используем команду peer ACCESS_1 next-hop-local. Это важно, иначе адрес next hop, в сообщении BGP Update для VPLS (если точнее, вот здесь - MP_REACH_NLRI > next hop network address), будет меняться на адрес RR, который участвовал в пересылке. Таким образом, пользовательского трафика между access-1 и access-2 не будет. А весь широковещательный пользовательский трафик будет отрабсываться на ближайшем RR, т.к. на них не настроен vsi, а если и настроим, то split horizon не позволит передать трафик дальше, чем конкретный RR (см. картинку “Принципы распространения трафика в VPLS”).
Ещё один важный момент: BGP будет заниматься автопоиском vpls-соседей и раздачей сервисных меток. Что же касается транспортного LSP и транспортных меток, то это все само не появится. Здесь ничего нового, но между устройствами нужно либо настроить RSVP-TE туннель, либо использовать LDP. Второй вариант настраивается заранее и не требует дополнительных туннелей, это удобно и вместе с BGP AD выглядит здорово. Но если нужна гибкость RSVP-TE, то между access-1 и access-2, нужно вручную настроить соответствующий Tunnel-интерфейс (пример настройки где-то там, выше).
По аналогии настраивается access-2.
4. В пределах access-1:
В Huawei, как Martini, так и Kompella VPLS, поддерживают локальную связность, поэтому ничего не мешает настроить vsi на любом access-устройстве и связать его с интерфейсами этого же устройства. Всё будет работать.
Полезные команды
display cur conf vsi vsi_name - проверить конфигурацию vsi с именем vsi_name. Если не указать имя, то увидим конфигурацию всех vsi, созданных на устройствe
display vsi name vsi_name verbose - проверить конфигурацию vsi детально. Здесь много полезной информации о том, как сконфигурирован vsi на устройстве. Выше уже была описана эта команда.
display vpls connection - проверить состояние всех VC для vsi, узнать сервисные метки.
display vsi pw out-interface vsi vsi_name - проверить vcid и исходящий интерфейс для соседей по vsi
display mpls label-stack vpls vsi vsi_name peer 10.1.0.2 vc-id 2 - проверить весь стек меток для интересующего VC (сервисная + транспортная). Актуально для Martini VPLS
display vsi name vsi_name peer-info - проверить сервисные метки для соседей по vsi (актуально для статически настроенных соседей в Martini mode)
display mpls lsp - проверить транспортные метки
display mac-address vsi vsi_name - просмотр mac-адресов в vsi
display l2vpn vsi-list tunnel-policy policy-name - проверить, используют ли какие-то vsi туннельные политики
display traffic-statistic vsi vsi_name - просмотр статистики по трафику в vsi. Предварительно нужно включить в vsi
display vpls forwarding-info verbose - проверить сервисные метки, исходящий интерфейс, vc-id, состояние PW для всех соседей по vsi. Удобная команда.
display bgp l2vpn-ad routing-table vpls - проверить маршруты для l2vpn-ad-family c vpls signaling. Этой командой можно узнать, отправляются BGP Update или нет
tracert vpls - тот же tracert, но для vpls, проверяем lsp-хопы для VC
ping vpls - по аналогии с tracert
ce-ping 10.1.1.1 vsi vsi_name source-ip 10.1.1.2 - ping CE-устройства с удаленного РЕ для проверки связности через VPLS-домен. Source и destination IP должны быть в одном IP-сегменте
display mpls te tunnel path - покажет полный LSP со всеми хопами и соответствующими метками. Чтобы это работало, на туннельном интерфейса должна быть включена команда mpls te record-route
display vsi services vsi_name - посмотреть интерфейсы, привязанные к vsi_name